LLM Integration Architecture: How to Add AI to Your Existing Product Without Breaking It
Learn how to integrate LLMs into existing products with scalable architecture, RAG, observability, guardrails, and AI orchestration best practices.
Table of Contents
Introduction
The pressure to integrate AI into digital products has never been higher. Customers expect intelligent search, AI copilots, automated workflows, document analysis, and personalized experiences. Customers increasingly expect AI capabilities to be built directly into existing products, turning AI from a competitive advantage into a baseline product requirement.
As a result, many organizations find themselves facing the same question:
How do we add AI to an existing product without compromising reliability, security, scalability, or development velocity?
The answer is rarely about choosing the right model.
Most integration challenges emerge long after the first successful API call. Teams discover that introducing LLMs into production systems creates a new category of architectural concerns: non-deterministic outputs, context management, evaluation pipelines, vendor dependencies, observability requirements, and cost governance.
In other words, adding AI is not a feature development problem. It is a systems architecture problem.
Organizations that successfully scale AI capabilities understand a critical principle: language models should be treated as infrastructure components within a larger system, not as standalone solutions.
Why LLMs Change Architectural Assumptions
Traditional software systems are built around deterministic behavior. Given the same inputs, the system produces the same outputs. Database queries return predictable results. Business rules execute consistently. APIs behave according to well-defined contracts.
LLMs operate differently. Their outputs are probabilistic by design. Response quality depends on prompt structure, available context, model configuration, retrieval quality, and underlying provider behavior. Even minor changes in any of these variables can produce significantly different outcomes.
This introduces a challenge that most engineering teams have never had to solve before. The system remains deterministic. One of its most important components does not.
Treating an LLM as just another microservice often leads to fragile architectures because traditional service design patterns assume predictability. AI systems require an additional layer responsible for controlling uncertainty, validating outputs, and maintaining operational reliability.
The organizations seeing the greatest success with AI are not eliminating uncertainty. They are designing systems that can safely operate despite it.
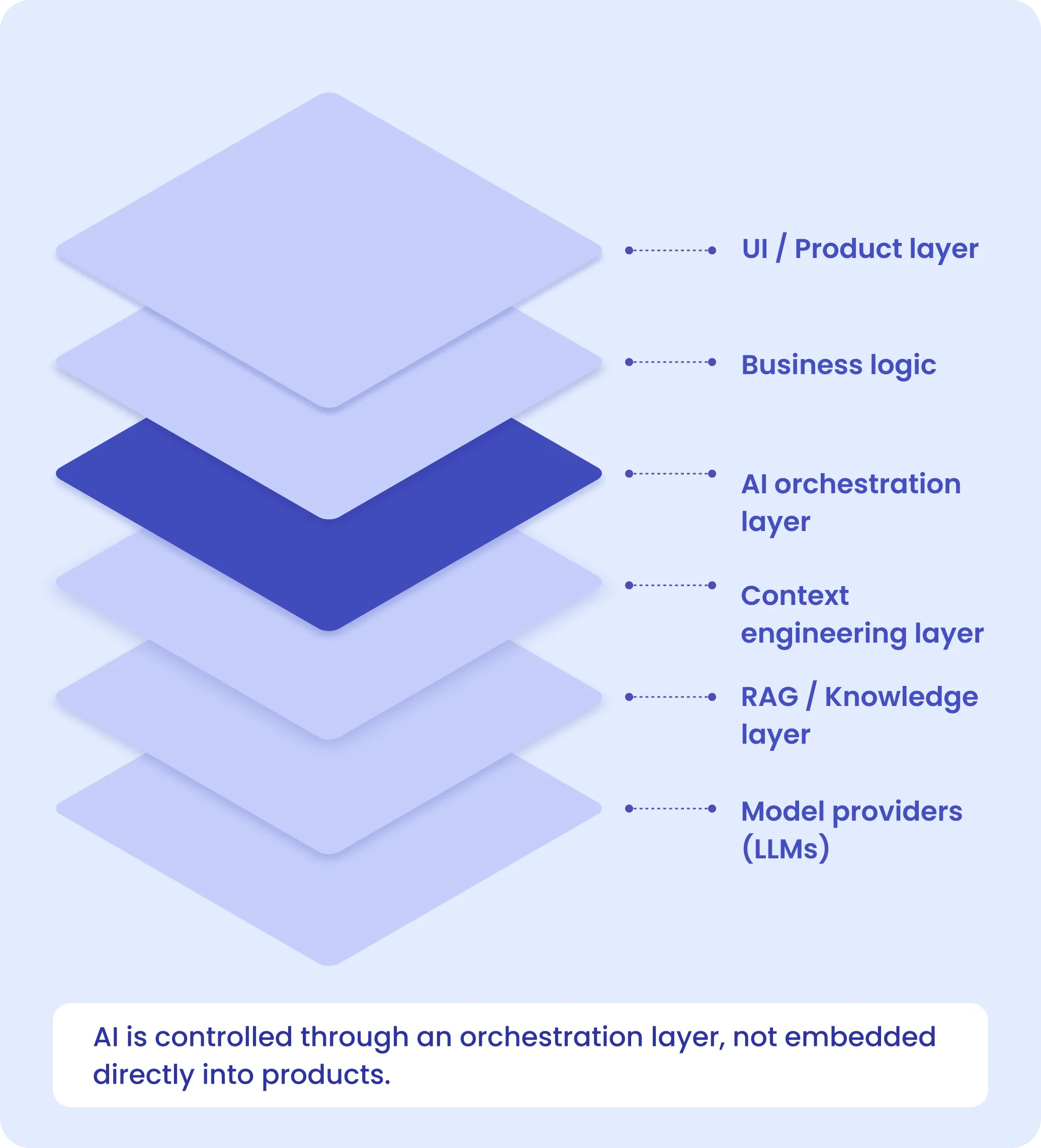
The AI Orchestration Layer: A New Architectural Boundary

One of the most common mistakes in early AI projects is allowing application services to communicate directly with model providers.
While this approach accelerates initial development, it quickly creates operational complexity. Prompt logic becomes scattered across services. Different teams implement inconsistent patterns. Model-specific behavior leaks into business logic. Upgrading providers becomes expensive and risky.
A more sustainable approach is introducing a dedicated AI orchestration layer between application services and model providers. This layer functions as the control plane for all AI interactions. Rather than simply forwarding requests, it becomes responsible for:
- Prompt management
- Context assembly
- Model routing
- Tool execution
- Response validation
- Observability
- Cost optimization
- Fallback handling
As AI adoption expands across the organization, the orchestration layer often evolves into an internal platform serving multiple products and teams.
This separation provides a crucial architectural advantage: business services remain focused on domain logic while AI-related complexity remains isolated within a dedicated layer.
Context Engineering Is Becoming a Core Discipline
Many AI discussions focus on model selection. In practice, model choice is often less important than context quality.
Organizations frequently assume that poor AI performance indicates a need for larger models or fine-tuning initiatives. In reality, the root cause is usually inadequate context management.
Modern LLM applications depend heavily on how information is retrieved, filtered, prioritized, and presented to the model. Questions that rarely existed in traditional software architecture suddenly become critical:
- Which information should be retrieved?
- Which sources should be trusted?
- How much context should be provided?
- What should be excluded?
- How should historical interactions be summarized?
- How should conflicting information be resolved?
Together, these decisions form the discipline known as context engineering. Poor context engineering creates expensive systems that remain unreliable regardless of model quality.
Strong context engineering enables smaller and more cost-efficient models to outperform larger models operating with insufficient or poorly structured information.
Retrieval-Augmented Generation Before Fine-Tuning
One of the most persistent misconceptions in enterprise AI is the belief that fine-tuning is the primary path toward domain expertise. For most organizations, this assumption is incorrect.
The majority of business applications don’t suffer from a reasoning problem. They suffer from a knowledge access problem.
Foundation models already possess broad reasoning capabilities. What they lack is access to proprietary organizational knowledge: internal documentation, contracts, support tickets, operational procedures, compliance policies, and customer-specific data.
Retrieval-Augmented Generation (RAG) addresses this challenge by separating knowledge storage from reasoning. Instead of embedding information directly into model weights, relevant content is retrieved dynamically and supplied during inference.
This architectural approach offers several important advantages:
- Knowledge can be updated immediately without retraining models.
- Responses become traceable to source documents.
- Hallucination rates are reduced because the model operates on authoritative information.
- Maintenance costs remain significantly lower than fine-tuning pipelines.
Retrieval architectures also align better with how organizations manage information in the real world. Knowledge changes continuously. Models shouldn’t need retraining every time documentation is updated.
For most production systems, RAG is a prerequisite, not an optimization.
Design for Model Independence
The AI ecosystem evolves quickly. Models improve, pricing changes, and providers introduce new capabilities at a rapid pace.
To avoid tight coupling, AI systems should isolate model interactions behind an abstraction layer. This ensures that changes in underlying models do not require changes in application logic.
Vendor flexibility is not an optimization — it is a long-term architectural constraint.
Observability Is No Longer Optional
Many organizations underestimate the operational complexity of AI systems. Traditional monitoring frameworks focus on metrics such as latency, throughput, infrastructure utilization, and error rates.
While these remain important, they provide only a partial picture of system health. AI systems introduce entirely new operational questions:
- Are responses accurate?
- Are retrieval pipelines returning relevant information?
- Has model quality degraded after an update?
- Which prompts perform best?
- How much does each workflow cost?
- Where are hallucinations occurring?
Without visibility into these dimensions, organizations lose the ability to improve AI performance systematically. Mature AI platforms increasingly treat observability as a first-class architectural concern. This often includes:
- Prompt version tracking
- Response quality evaluation
- Retrieval performance monitoring
- Cost analytics
- User feedback signals
- Automated regression testing
The goal is not simply monitoring infrastructure. The goal is monitoring reasoning quality.
Guardrails Must Be Part of the Architecture
One of the defining characteristics of production AI systems is that they cannot be trusted blindly. Unlike conventional software, correctness cannot always be guaranteed through deterministic logic.
As a result, successful implementations rely on layered guardrails.
- Input validation protects against prompt injection attempts, malformed requests, and unsupported use cases.
- Context validation ensures that retrieved information meets relevance and quality thresholds.
- Output validation verifies structure, formatting, business constraints, and policy compliance.
For high-risk workflows, additional review layers may be required before responses reach end users.
The most effective AI architectures assume that failures will occur and focus on detecting, containing, and mitigating those failures before they create business impact.
This mindset closely resembles modern cybersecurity practices. The objective is not eliminating risk entirely. The objective is building systems that remain safe when failures inevitably occur.
Security, Compliance, and Data Governance
AI introduces new data flows across orchestration layers, retrieval systems, vector databases, and model providers. As a result, governance requirements should be addressed at the architectural level rather than through isolated security controls.
For regulated industries, this often leads to hybrid deployments where sensitive workloads remain within private infrastructure while external models are used selectively.
These decisions become especially critical when proprietary or regulated data is involved, as compliance constraints often define the architecture more strictly than technical considerations.
AI Evaluation Is the Missing Layer in Most Architectures
The most overlooked layer in production AI systems is evaluation.
Unlike traditional software, AI systems cannot be validated through deterministic testing alone. A feature may work correctly from an engineering perspective while producing lower-quality results than before. Without a way to measure quality, these regressions often go unnoticed until they affect users.
Each update can improve one aspect of performance while degrading another. Without a structured evaluation framework, teams are left relying on intuition rather than evidence.
Mature AI organizations address this by introducing continuous evaluation pipelines alongside traditional CI/CD processes. Benchmark datasets, representative user scenarios, and domain-specific metrics become part of the development lifecycle, making AI quality measurable and improvements verifiable.
Ultimately, evaluation is what transforms AI from an experimental capability into a manageable engineering system. As AI adoption matures, evaluation frameworks are becoming as essential as automated testing in traditional software development.
Final Thoughts
The companies creating the most value from AI are not necessarily those adopting the most advanced models, but those designing the most robust systems around them.
As organizations move from experimentation to production, the challenge shifts from model selection to system design. Modern language models are rapidly improving, but capability alone does not guarantee reliable or repeatable business outcomes. What consistently determines success is whether AI is treated as part of the system architecture, not as a feature layer.
At the same time, the AI landscape remains inherently unstable. Models evolve, providers compete, pricing shifts, and implementation patterns change. Systems that are tightly coupled to specific model behaviors or vendor interfaces inevitably accumulate technical friction and migration cost. In contrast, well-designed integration architectures absorb change without forcing product-level rewrites.

The objective is not to “add AI” to a product. It is to establish an architecture where intelligence becomes an evolvable capability rather than a fixed dependency.
Ultimately, the distinction between successful and failed AI products is not model quality, but architectural discipline. The winners will not be those who integrate AI fastest, but those who design systems where intelligence can evolve without rewriting the product around it.



