Why Your AI Initiative Stalls After the PoC: A Data Readiness Primer for Product Teams
Discover why AI initiatives often stall after the PoC stage and how data readiness, architecture, and ownership can turn pilots into scalable, production-ready AI systems.

Table of Contents
If you’ve already invested in an AI pilot, you’ve likely seen the pattern: the demo works, early results look promising, stakeholders start to believe this could become a real product capability.
And then progress slows down — or stops entirely. The model doesn’t make it into production. Or it does, but it never reaches a level of reliability that the business can depend on. What looked like momentum turns into uncertainty.
This is where many teams get stuck. Not because the idea was wrong. Not because the model was weak. But because the system around it — data, architecture, and ownership — wasn’t ready.
If your AI initiative feels stalled after the PoC stage, you’re not alone. And more importantly, you’re likely dealing with a data readiness problem, not a modeling problem.
The Real Reason AI Pilots Don’t Scale
When teams search for answers to why AI projects fail, they often look in the wrong place — model performance, tools, or talent.
In practice, most AI pilot-to-production failures stem from three systemic gaps.
1. Data: Available in Theory, Unusable in Practice
On paper, your company has data. In reality, that data is fragmented, inconsistent, and difficult to operationalize.
Common patterns we see:
- Data spread across multiple systems (CRM, product analytics, internal tools)
- Inconsistent schemas and definitions between teams
- Missing or incomplete historical data
- Lack of labeling or structured features
During a PoC, teams compensate manually:
- Exporting datasets into spreadsheets
- Cleaning and transforming data offline
- Making assumptions that are never formalized
This is enough to prove a concept, but it is not enough to support a production system that depends on continuous, reliable data flows.
2. Architecture: No Bridge from Experiment to Production
PoCs are intentionally lightweight. They don’t require production-grade infrastructure, which is exactly why they don’t translate easily into production.
Typical gaps include the absence of automated data pipelines, unclear separation between raw, processed, and feature data, lack of dataset or model versioning, missing monitoring for model inputs and outputs, and no integration strategy with existing systems.
The result is predictable: you have a working model — but no way to deploy, maintain, or scale it. Without a proper data and MLOps layer, the model remains an isolated artifact rather than a product feature.
3. Team & Ownership: AI Lives “Between” Functions
AI initiatives often fall into an ownership gap: data science builds the model, engineering owns the product, and product defines the use case — but no one takes responsibility for the AI system as a whole in production.
This leads to:
- No accountability for model performance over time
- No clear iteration loop
- AI work is constantly deprioritized against core roadmap items
In this setup, AI remains experimental by default.
What “Data Readiness” Actually Means (and Why Most Teams Skip It)
“AI readiness” is often discussed in abstract terms. But in practice, it starts with something much more concrete: data readiness. Data readiness defines whether your system can support AI beyond a one-time experiment.
It can be broken down into four key dimensions.
1. Availability
Can your data be accessed reliably and programmatically?
- Is it available via APIs or pipelines, not manual exports?
- Are access controls and ownership clearly defined?
- Can your system retrieve data on demand?
Typical gap: Data exists, but requires manual effort or approvals to access.
2. Quality
Is your data trustworthy enough for automated decision-making?
- Are there inconsistencies between sources?
- How are missing values handled?
- Are definitions aligned across teams?
Typical gap: Data is “good enough” for dashboards, but not for models that depend on consistency.
3. Structure
Is your data organized in a way that can be reused and scaled?
- Are schemas consistent and documented?
- Is feature engineering reproducible?
- Can you rebuild datasets without starting from scratch?
Typical gap: Each experiment requires custom preprocessing.
4. Coverage
Does your data reflect real-world conditions?
- Is there sufficient historical depth?
- Are edge cases represented?
- Does the data cover the full range of user behavior?
Typical gap: Models perform well in controlled scenarios, but fail in production variability.
What “Ready” Actually Looks Like
Data readiness does not mean perfect data. It means your data pipelines are automated and observable, transformations are reproducible, schemas are stable enough to build upon, and known quality issues are tracked and manageable. In other words, your data becomes a reliable component of the system rather than a one-off input to experiments.
Why Teams Skip This Step
Despite its importance, data readiness is often overlooked because it doesn’t produce immediate visible results, is often perceived as infrastructure work rather than product progress, PoC success can create a false sense of readiness, and internal teams are already overloaded with roadmap priorities.
This is also where risk accumulates. Teams move forward assuming they are “close to production” — only to discover that foundational gaps require significant rework.
A Practical Checklist: Is Your Data Ready for AI?
Before investing further in scaling your AI initiative, it’s worth running a quick self-assessment.
If several of these answers are unclear or negative, your project is likely to stall again — regardless of model quality.
- Can all required data sources be accessed programmatically (without manual exports)?
- Do we have consistent definitions for core entities (users, transactions, events)?
- Is our data pipeline automated and reproducible?
- Can we trace how a dataset was created (data lineage)?
- Do we monitor data quality over time?
- Do we have enough historical data for real production scenarios?
- Can models be retrained and redeployed without manual rebuilding?
- Is there a clear owner responsible for AI in production?
This checklist is not about perfection. It’s about visibility.
If you don’t know the answers, that’s already a signal.
How to Move from PoC to Production: The Foundations-First Approach
If the root cause of failure is not the model, then scaling AI requires a different starting point.
At JetRuby, we approach AI initiatives with a Foundations-first methodology — focusing on data readiness and architecture before building complex models.
This reduces risk, avoids wasted investment, and creates a realistic path from AI pilot to production.
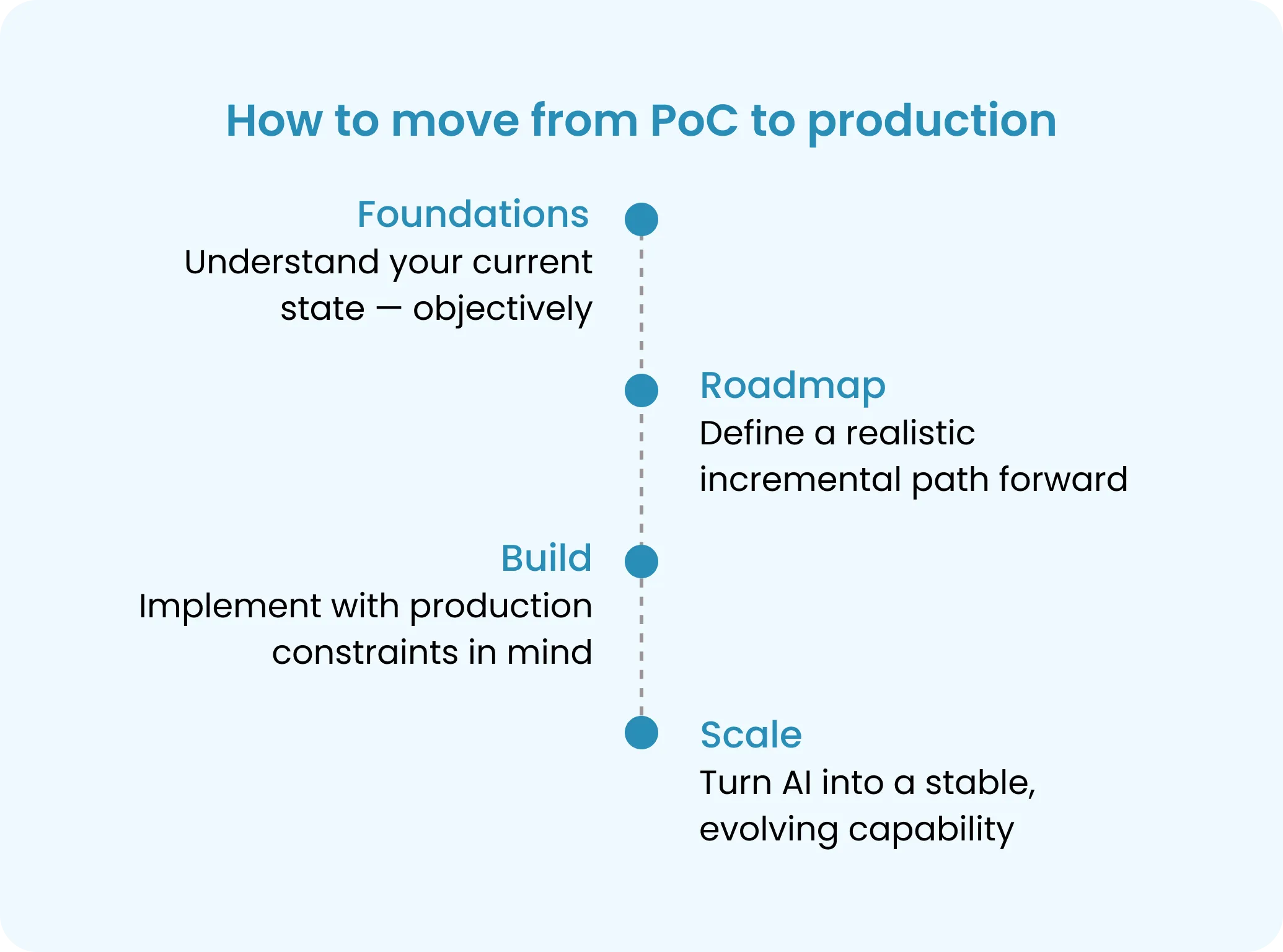
1. Foundations
Goal: Understand your current state — objectively.
This phase includes:
- Data audit (sources, formats, quality issues)
- Architecture review (pipelines, storage, integrations)
- Identification of critical gaps preventing scaling
Key questions answered:
- What data do we actually have?
- What condition is it in?
- What blocks us from using it in production?
Output:
- Clear data readiness assessment
- Architecture gap analysis
- Prioritized list of foundational improvements
This step is critical for teams that want to avoid committing to expensive builds without clarity on outcomes.
2. Roadmap
Goal: Define a realistic, incremental path forward.
Instead of jumping into development, this phase aligns technical decisions with business goals.
It includes:
- Designing data pipelines and storage layers
- Defining MLOps strategy (versioning, deployment, monitoring)
- Breaking down delivery into manageable stages
Output:
- A step-by-step plan from the current state to production
- Clear trade-offs between speed and robustness
- Alignment between product, engineering, and data teams
This is where many AI initiatives either gain clarity — or reveal that they are not ready to proceed yet.
3. Build
Goal: Implement with production constraints in mind.
Instead of building isolated models, the focus shifts to system design:
- Production-ready data pipelines
- Modular, maintainable architecture
- Reproducible training and deployment workflows
The model is treated as one component within a larger system.
This significantly reduces the risk of having to rebuild everything later.
4. Scale
Goal: Turn AI into a stable, evolving capability.
At this stage:
- Model performance is monitored in real-world conditions
- Feedback loops drive continuous improvement
- New use cases can be added on top of existing infrastructure
AI transitions from an experiment to a core part of the product.
What This Looks Like in Practice
In real projects, moving from PoC to production often begins with uncovering opportunities to strengthen the product and its infrastructure.

In the case of MyManifest, the initial idea was to create a platform that gives individuals and households a unified, real-time view of their financial lives. The client started with a clickable prototype for investors, but collaboration with JetRuby revealed the full potential of the concept.
Key positive outcomes included:
- Structured product vision: Through workshops and discovery sessions, the team translated a high-level concept into clearly defined user flows, prioritized features, and a realistic scope.
- Robust data architecture: The platform was designed to aggregate financial data reliably, leveraging hybrid methods that combine automated aggregation, manual input, and data normalization pipelines. This ensured consistent performance under real-world conditions.
- Scalable, modular system: The architecture reflected the product decisions, supporting future growth, evolving features, and secure, compliant handling of sensitive data.
- Investor-ready prototype: The PoC focused on well-defined user scenarios, clearly demonstrating the platform’s core value and enabling confident investor presentations.
- Product-driven Discovery: The process helped the client uncover the true complexity of their product, prioritize what matters most, and establish a clear path from concept to MVP and beyond.
The MyManifest project demonstrates how a PoC can evolve into a strong foundation for a scalable, reliable product when product vision, architecture, and data readiness are aligned from the start.
Progress did not come from improving algorithms.
It came from building a strong product foundation, aligning architecture with real-world data, and structuring validated user flows.
Wrap-up
If your AI initiative is poised to move beyond the PoC, the key to success is rarely the model itself. True progress comes from building a solid foundation — aligning product vision, data architecture, and scalable design.
Understanding your data readiness and addressing gaps early transforms experimental pilots into reliable, production-ready capabilities. It’s the difference between a promising concept and a product that can evolve, grow, and deliver real value over time.
Before moving forward, ask yourself:
Are we ready to turn AI into a core part of our product — or are we only demonstrating an idea?
When the foundation is strong, the model becomes just one component of a system designed to succeed, scale, and create meaningful impact.
Not sure where your data stands? Let’s find out together.
Share a brief overview of your product and data — we’ll come back with an honest assessment and a realistic next step.



