Turning Data into Defensible AI IP with Data Engineering and MLOps
Explore how to turn data into defensible AI-driven intellectual property using advanced AI systems, data engineering, MLOps, and GenAI platforms. Learn how scalable ML infrastructure and production-grade AI transform experiments into competitive business assets.
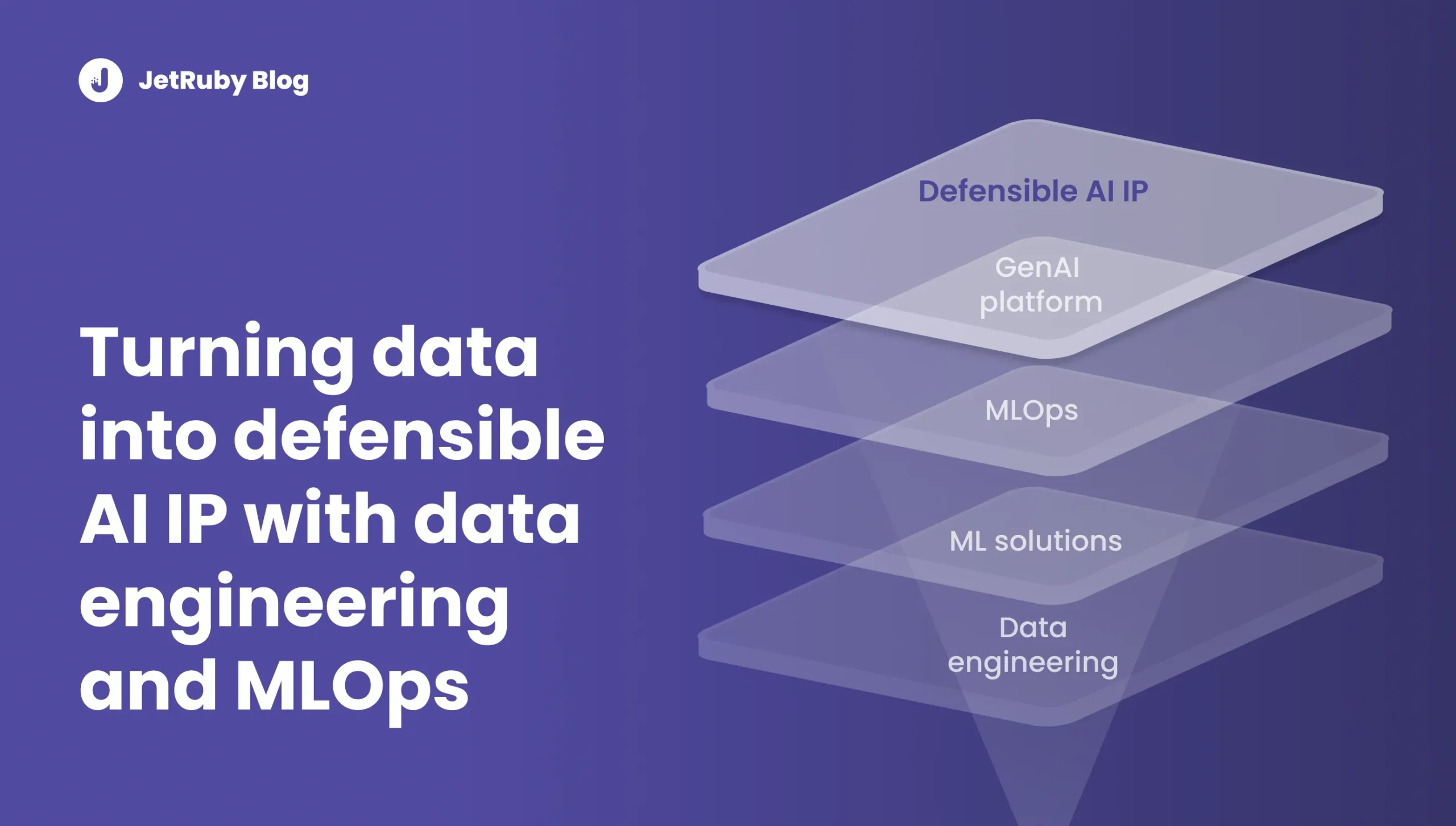
Table of Contents
Introduction: When Basic AI Is Not Enough, and AI Becomes Core IP
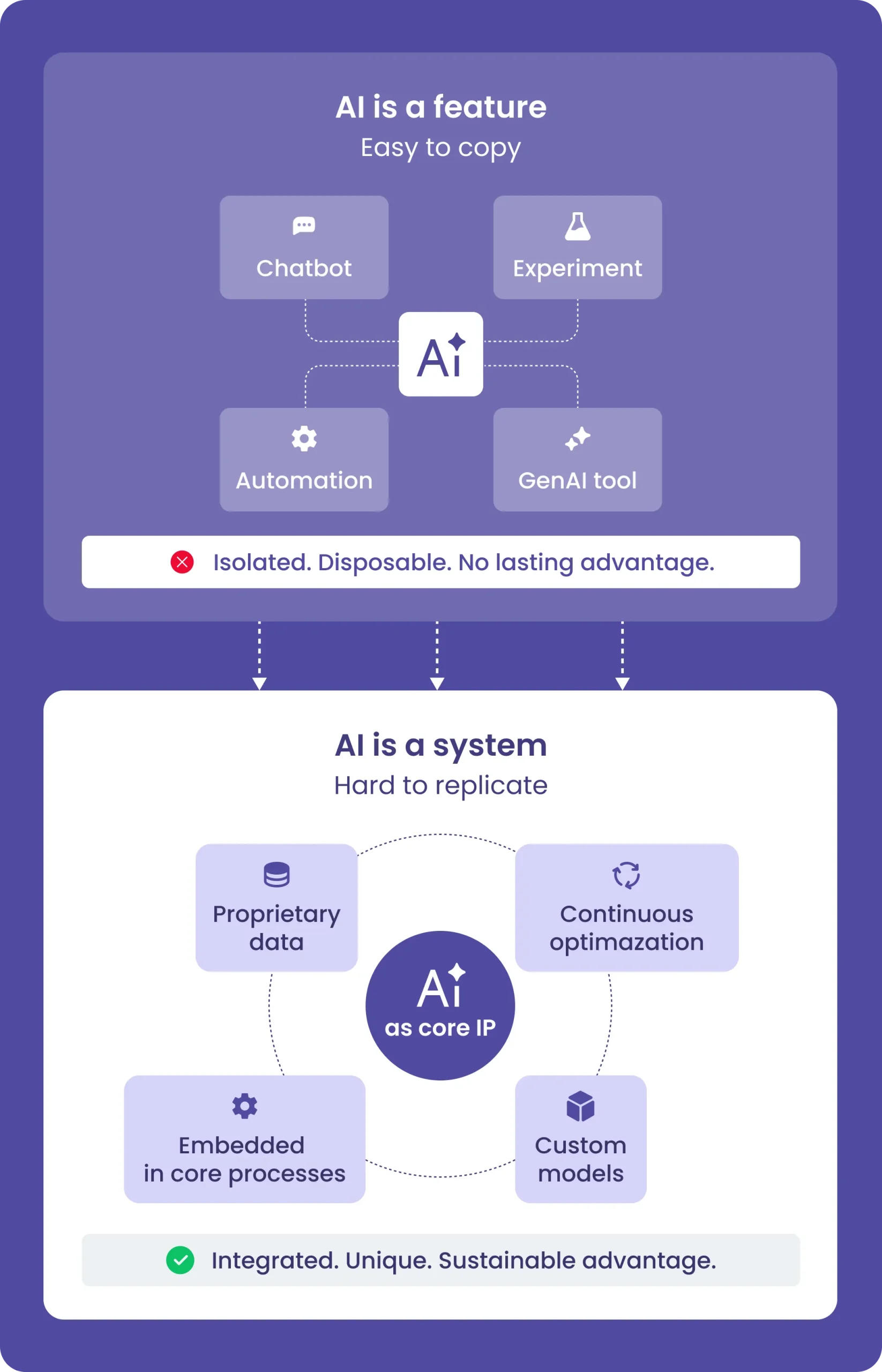
Most companies today have already experimented with AI. They’ve launched chatbots, built internal copilots, or automated workflows using LLMs. These basic AI applications are relatively easy to implement and often deliver quick wins.
But they rarely create a lasting competitive advantage. As organizations grow and accumulate more data, a more strategic question emerges:
How do we turn our data and AI capabilities into something competitors cannot easily replicate?
This is where advanced AI applications come into play.
Unlike basic AI, which typically sits as a thin layer on top of existing systems, advanced AI becomes deeply embedded into core business processes. It relies on proprietary data, custom models, and continuous optimization. Over time, it evolves into AI-driven intellectual property (AI as core IP) — a strategic asset that compounds value and becomes increasingly difficult to reproduce.
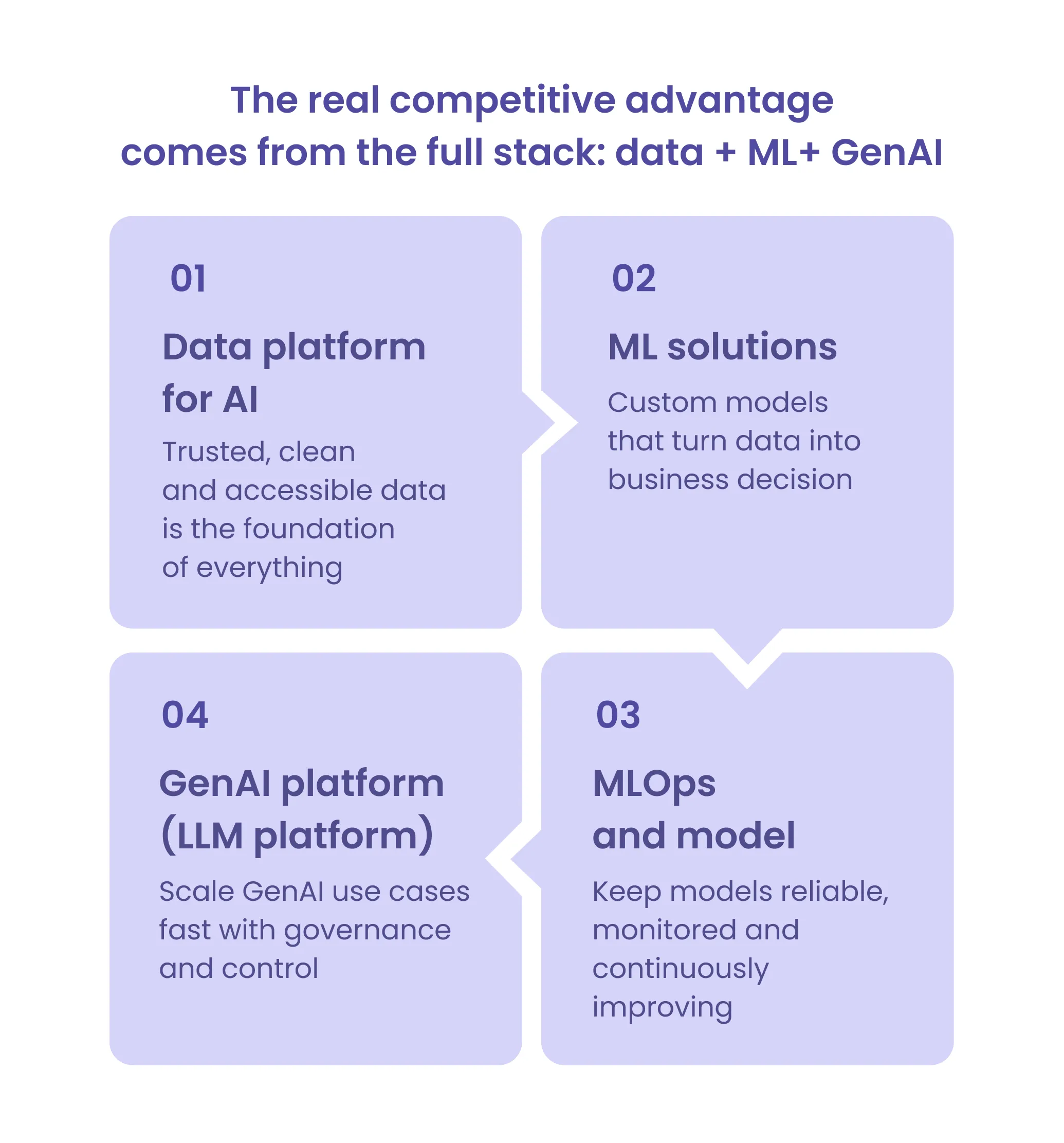
However, building AI as core IP is not about adding more tools or experimenting with more models. It requires a solid, system-level foundation:
- A scalable data platform for AI
- Production-grade ML solutions for forecasting, pricing, and risk scoring
- Robust MLOps and model lifecycle management
- A structured GenAI platform (LLM platform)
Without these elements, AI initiatives remain fragmented — and ultimately easy to copy.
Why Data Engineering Is the Non-Negotiable Foundation for Serious AI
One of the most common reasons AI initiatives fail is not model quality — it’s data quality. Without proper data engineering for AI, organizations quickly run into systemic issues that undermine any downstream AI efforts.
In practice, this often results in:
- conflicting metrics across teams,
- incomplete or delayed pipelines,
- poor data discoverability,
- and “shadow datasets” created in isolated experiments.
In such environments, even the most advanced models struggle to deliver reliable results. Instead of generating insights, they amplify inconsistencies. With LLMs, this typically manifests as confident but incorrect outputs — effectively hallucinations grounded in unreliable data.
A production-grade data platform for AI addresses this by creating a unified and governed data layer. It consolidates transactional, behavioral, and operational data into a single source of truth, whether implemented as a data warehouse, data lake, or lakehouse. On top of this foundation, ingestion and transformation pipelines — both batch and real-time — ensure that data flows continuously and remains consistent.
Equally important is the governance layer. Data quality checks, monitoring systems, lineage tracking, and role-based access control ensure that data is not only available but trustworthy and auditable. A well-implemented data catalog improves discoverability, while the BI layer aligns teams around consistent business metrics.
To move from fragmented data to a usable foundation quickly, many companies start with a focused data-readiness sprint. This 2–4 week phase is designed to create clarity and momentum without overengineering.
Typical outputs include:
- a high-level data architecture,
- an inventory of data sources and quality gaps,
- initial ingestion and transformation pipelines,
- defined data models for priority use cases,
- a data quality report,
- and a prioritized AI roadmap.
The impact is immediate and measurable. Teams often see a 30–50% reduction in time to access reliable data, elimination of inconsistent reporting, and significantly faster experimentation cycles. More importantly, they gain a predictable and reproducible data layer — the foundation for any serious advanced AI application.
Classic ML Solutions: When You Need Accurate Predictions, Not Chat
While LLMs have expanded what’s possible, they are not designed for deterministic, high-stakes decisions. In many business-critical scenarios, traditional ML solutions for forecasting, pricing, and risk scoring remain the most effective approach.
These models are built for structured data, measurable accuracy, and direct integration into operational systems. Instead of generating text, they produce decisions — prices, scores, priorities — that directly impact revenue, cost, and risk.
For example, in demand forecasting and dynamic pricing, models analyze historical sales, seasonality, and promotional activity to generate recommendations that feed directly into commerce systems. In mature implementations, this can drive margin improvements of 5–10% while reducing stockouts.
In fintech or insurance, risk scoring and fraud detection models process transaction histories and behavioral signals to generate real-time scores. These outputs trigger automated actions such as approvals or fraud alerts, often resulting in a 15–30% reduction in fraud losses.
Other common use cases include churn prediction, where models identify at-risk users and trigger retention workflows, and logistics optimization, where routing and capacity planning models reduce operational costs while improving SLA performance.
What distinguishes advanced AI applications is not just the model itself, but its integration. Models are embedded directly into business workflows, their outputs drive automated decisions, and their performance is measured in business KPIs — not only technical metrics.
This is the point where machine learning stops being an experiment and becomes AI as core IP.
MLOps and Model Lifecycle Management: Keeping Models Alive
A deployed model is not a finished product — it is a living system that changes over time. As user behavior shifts, markets evolve, and data distributions drift, model performance inevitably degrades.
Without proper MLOps and model lifecycle management, this degradation often goes unnoticed until it starts affecting business outcomes.
Typical warning signs include:
- silent drops in model accuracy,
- lack of clarity around which model version is in production,
- manual and inconsistent retraining processes,
- and the inability to safely roll back changes.
A mature MLOps setup addresses these risks by turning model management into a structured, repeatable process. It introduces CI/CD pipelines for automated testing and deployment, a model registry for version control and promotion across environments, and monitoring systems that track both technical metrics (like drift) and business KPIs.
At the same time, feature and data versioning ensure reproducibility, while access control and audit mechanisms provide transparency and compliance.
With these practices in place, organizations gain:
- faster iteration cycles (often 2–3x improvement),
- early detection of performance degradation,
- and increased trust in AI-driven decisions.
This operational reliability is essential for scaling advanced AI applications beyond isolated use cases.
Building a GenAI Platform: LLM as a Capability, Not a Feature
As organizations scale their use of LLMs, a new challenge emerges: fragmentation. Different teams build their own agents, prompts, and integrations, leading to duplication, inconsistent quality, and rising costs.
Without a structured GenAI platform (LLM platform), this quickly turns into operational chaos:
- dozens of disconnected agents,
- no centralized prompt management,
- unpredictable API costs,
- lack of evaluation standards,
- and growing security risks.
A dedicated GenAI platform addresses this by treating LLM use as a managed internal capability. Instead of isolated scripts, organizations build a shared layer that standardizes how models are used across the company.
This typically includes:
- model routing to select the best model for each task,
- prompt management with versioning and governance,
- evaluation frameworks (evals) to measure output quality,
- logging and observability for full traceability,
- security controls and RBAC,
- cost management mechanisms,
- and a sandbox for safe experimentation.
With such a platform in place, companies can launch new use cases 2–4x faster, maintain consistent quality, and keep costs under control. More importantly, they avoid the fragmentation that prevents AI from scaling.
How These Components Become Defensible AI-Driven Intellectual Property
Individually, each layer — data, models, operations, and GenAI—provides value. Together, they form a system that is extremely difficult to replicate.
- Proprietary data becomes a data platform for AI
- Custom models become embedded decision engines
- MLOps ensures continuous improvement
- The GenAI platform enables scalable experimentation and deployment
This combination creates AI-driven intellectual property that is:
- hard to copy,
- continuously improving,
- and deeply integrated into business operations.
In e-commerce, this might mean a tightly coupled system in which demand forecasting, pricing, and personalization operate on a unified data platform and are extended via a GenAI layer for internal users. In fintech, it can take the form of risk and fraud models managed as products, continuously monitored and improved through MLOps.
In both cases, AI is no longer an add-on — it becomes part of the company’s core value proposition.
Engagement Path: From Data Readiness Sprint to Full AI Platform
Building advanced AI applications does not require a “big bang” transformation. A phased approach allows organizations to move forward with controlled risk while delivering measurable value at each step.
A typical journey starts with a data-readiness sprint, during which the foundation for AI data engineering is established, and high-impact opportunities are identified. From there, teams prioritize use cases and move into pilot implementations, delivering one or two production-ready ML or GenAI solutions tied to business metrics.
As these solutions prove their value, the focus shifts toward scaling — expanding into a full data platform for AI, implementing MLOps and model lifecycle management, and building a reusable GenAI layer.
Key deliverables along this path include:
- data architecture and pipelines,
- production-ready ML models with defined KPIs,
- initial MLOps setup (registry, monitoring, CI/CD),
- and a roadmap for scaling AI capabilities.
This structured approach ensures that AI investments translate into real systems — not isolated proofs of concept.
Next Steps: How to Explore Advanced AI with Low Risk
For organizations that already have data and early AI experiments, the next step is not more prototypes — it’s building a system.
A Data & AI Readiness call is a practical starting point. It helps assess the current state of data engineering for AI, identify gaps in ML and GenAI capabilities, and evaluate the potential to build AI as core IP.
From there, a short data-readiness sprint or an architecture review provides a clear, low-risk path toward scalable, advanced AI applications.
Advanced AI is not about isolated tools or one-off models. It is about building integrated systems where data, models, and infrastructure work together — and improve over time.
Companies that invest in strong data engineering, production-grade ML, and MLOps and model lifecycle management, combined with a scalable GenAI platform, are not just adopting AI; they are embracing it.
They are building defensible, AI-driven intellectual property that defines their competitive edge.
If you’re evaluating how to move from fragmented AI experiments to a scalable, production-ready system, a focused conversation is often the fastest way to get clarity.
- Review your current data and ML landscape
- Identify high-impact AI use cases with clear ROI
- Outline a realistic path from pilot to full AI platform
👉 Book a Data & AI Readiness call to explore how your existing data can be transformed into sustainable AI capabilities.



