LLM Integration in a Product You Already Ship: Architecture Decisions That Will Cost You Later
Integrating LLMs into an existing product is more than adding an API. Learn how to avoid vendor lock-in, latency issues, poor output quality, and compliance risks with scalable generative AI architecture patterns for SaaS.

Table of Contents
Integrating LLMs into an existing product is fundamentally different from building an AI-first system from scratch. In greenfield generative AI projects, you design architecture around probabilistic behavior from day one. In a mature SaaS product, you’re injecting that uncertainty into systems built for determinism: stable APIs, predictable latency, and testable logic.
That’s why LLM integration in SaaS products often fails not at the model level — but at the architecture level.
What starts as a simple “integrate GPT into a product” task quickly turns into a system-wide concern: latency impacts UX, output quality becomes inconsistent, and external dependencies start influencing core business logic.
At JetRuby, we’ve repeatedly seen the same pattern: teams ship fast, validate demand, and then spend months reworking foundational decisions that didn’t account for scale, compliance, or long-term flexibility.
This guide breaks down generative AI product architecture patterns, common failure modes, and the decisions that will either unlock or limit your system later.
Why LLM Integration Is Different from Adding Any Other Feature
Latency Becomes a Product Constraint
In typical backend systems, latency is an engineering metric. In LLM-powered features, it becomes a product decision.
In real systems, we see:
- 2–6 second response times under load
- Latency spikes due to long prompts or context windows
- Retry cascades when providers throttle requests
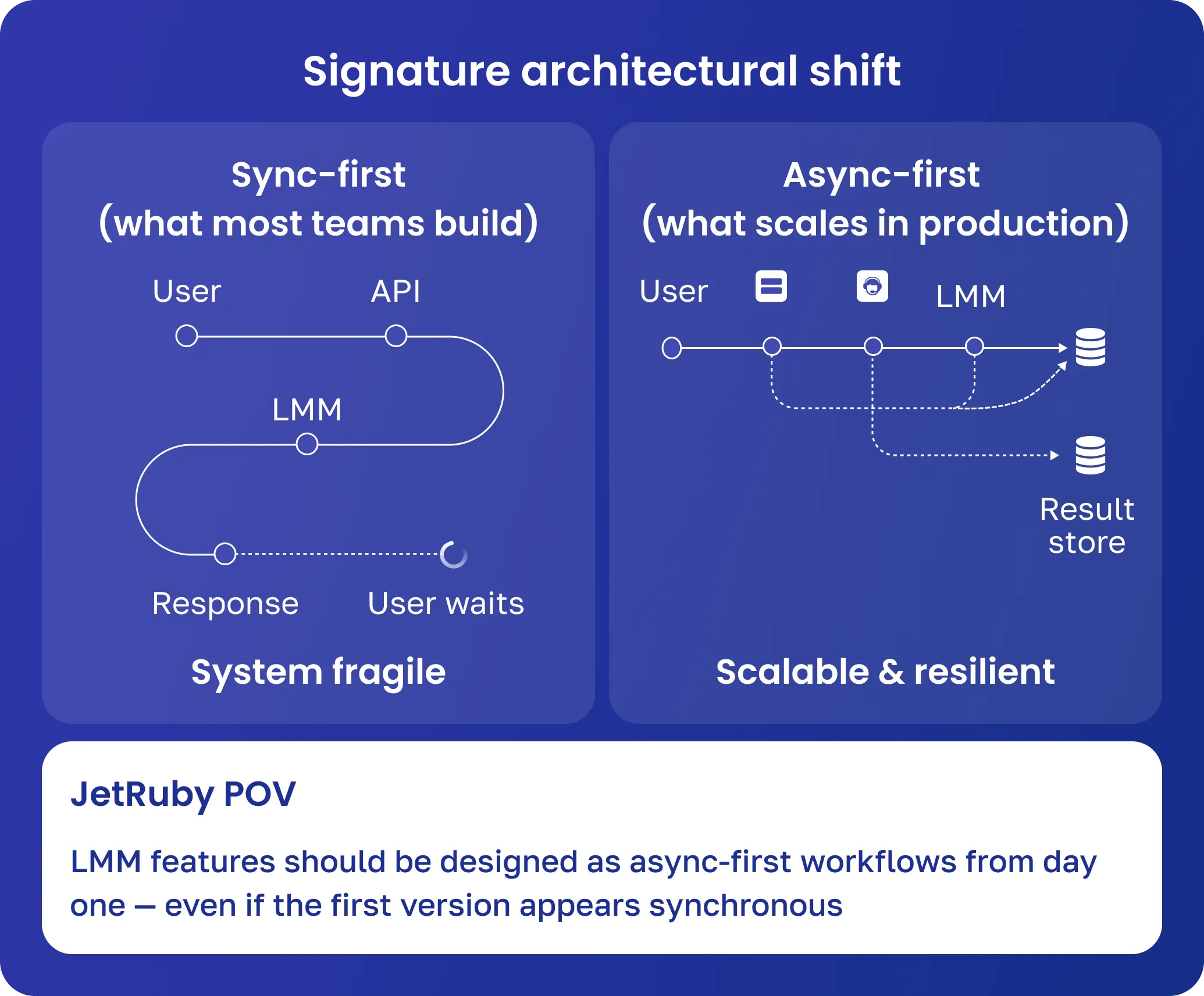
What breaks in production:
User request → LLM call → timeout → retry → duplicate requests → cost spike → degraded UX
This is one of the most common failure loops in LLM integration for SaaS.
JetRuby POV:
We recommend designing LLM features as async-first workflows (queues, streaming, background processing), even if the initial version appears synchronous.
External Dependency Becomes Core Logic
When you integrate GPT into a production system, you’re not just adding a dependency — you’re delegating part of your product logic to an external system.
What breaks:
- Model updates change output → parsing fails
- Rate limits → feature becomes unreliable during peak usage
- Pricing changes → AI feature becomes unprofitable
We’ve seen a case where a minor model update broke JSON formatting assumptions — causing downstream automation to fail silently for thousands of users.
Non-Determinism Breaks Traditional QA
LLMs introduce probabilistic behavior:
- Same input → different outputs
- Edge cases are not reproducible
- Bugs are semantic, not binary
What breaks:
- Snapshot tests become useless
- QA cannot reliably reproduce issues
- Rollbacks don’t restore behavior
Correct pattern:
Treat LLM systems as evaluated systems, not tested systems:
- Evaluation datasets instead of unit tests
- Output scoring instead of pass/fail
- Continuous monitoring instead of release validation
5 Architecture Decisions That Will Cost You Later
-
Direct LLM API Calls Without Abstraction
Common mistake: App → OpenAI API → Response. Fast to ship, but creates vendor lock-in. Later, switching providers requires rewriting prompts, there’s no fallback during outages, and cost optimization is impossible.
Better approach: App → LLM Gateway → Provider Adapters → Multiple LLMs. JetRuby’s view: Every production-grade LLM integration should start with a provider-agnostic layer, even for an MVP.
-
No Output Validation Layer
Mistake: Treating LLM output as reliable. This can lead to invalid JSON causing pipeline failures, hallucinated data reaching users, and compliance violations.
Better approach: Build a validation pipeline with schema checks, semantic filters, safety layers, and fallback/retry logic. JetRuby’s view: Systems should fail safely—if validation fails, degrade gracefully.
-
No Observability for AI Features
Mistake: Logging only requests and responses. Without proper observability, you can’t track prompt performance, detect model drift, or correlate issues with user experience.
Better approach: Add an AI observability layer with logging, metrics (prompt version, model version, latency, token usage, validation failures), and dashboards with alerts. JetRuby’s view: Treat prompts as versioned assets, not inline strings.
-
Ignoring Data Ownership
Mistake: Sending raw internal data to external LLM APIs. Risks include sensitive data leaks, loss of control over proprietary info, and GDPR violations.
Better approach: Introduce a data governance layer with preprocessing (masking, filtering, minimization), controlled LLM requests, and secure logging/storage. JetRuby’s view: Explicitly define what data is allowed to leave your system.
-
Ignoring Compliance in Regulated Domains
Many generative AI architectures fail when real-world compliance matters. Plan for regulatory constraints from the start to avoid costly redesigns.
A Note on Real Compliance Requirements
GDPR (EU / UK)
You must:
- Define roles (controller vs processor)
- Support data deletion requests
- Control cross-border data transfer
What breaks:
- No audit trail → cannot prove compliance
- Provider stores data → cannot delete
HIPAA (Healthcare)
You must:
- Protect PHI
- Sign Business Associate Agreements (BAA)
- Maintain audit logs
What breaks:
- Using public APIs without BAA
- Logging sensitive data
- No access tracking
Compliance-Aware Architecture
User data → Secure processing → Private/compliant LLM → Encrypted storage + audit logs
JetRuby POV: Even if compliance isn’t needed immediately, plan for it from day one—adding it later is often like rebuilding the whole system.
The Right Pattern: How to Build an LLM Integration That Scales
1. Provider-Agnostic Architecture
A scalable LLM setup separates responsibilities:
App → LLM Orchestration → Routing & Cost Optimization → Provider Adapters → OpenAI / Anthropic / Private LLM
This makes it easy to switch providers or add new ones without rewriting your app.
2. RAG vs. Fine-Tuning
RAG Architecture (Recommended)
User query → Retriever (vector DB/search) → Add context → LLM → Response
Best for: SaaS platforms, frequently updated data, lower cost, and faster iteration.
Fine-Tuning Architecture
Training Data → Model Training → Deployed Model → Inference
Trade-offs:
- Higher cost
- Slower iteration
- Increased vendor lock-in
JetRuby POV:
For most teams exploring how to integrate GPT into a product, RAG provides the best balance of flexibility and control.
3. Output Validation + Feedback Loop
User input → LLM → Validation → Output → Feedback (ratings, retries, drop-offs) → Evaluation → Prompt/model improvement.
Best practice: Use both explicit and implicit feedback, build evaluation datasets from real usage, and continuously refine prompts.
4. Minimum Viable MLOps for LLM Features
Sustainable LLM integration requires prompt and model versioning, evaluation datasets, regression testing, and canary releases. Advanced practices include shadow testing new prompts, offline vs. online evaluation, and drift detection pipelines.

A Note on Regulated Industries (Healthcare, Fintech)
In regulated environments, architecture decisions are constrained from day one.
What Breaks in Real Systems
- MVP built on public API → fails compliance audit
- Migration to private LLM → requires full rewrite
- Missing audit logs → blocks enterprise deals
Architectural Trade-offs
Private LLM deployment impacts:
- Latency (higher)
- Cost (infrastructure-heavy)
- Scalability (you own it)
JetRuby POV:
Design as if you already need compliance—even if you don’t yet.
Wrap-Up
LLM integration is about redesigning how your system handles uncertainty, external dependencies, and evolving behavior.
The difference between a successful implementation and a costly rewrite comes down to early architectural decisions:
- Abstract your providers
- Validate every output
- Monitor everything
- Control your data
- Design for compliance
Teams that get this right don’t just “add AI”—they build systems that can evolve with it.
Planning to add LLM to your product? Let’s review the architecture first.
Share your product context, current stack, and the AI feature you’re planning to build, and we’ll provide a practical architecture review, a risk map covering latency, cost, compliance, and vendor lock-in, and a recommended integration approach tailored to your product.
→ Talk to our AI & Data team



